
The architecture in hybrid scenarios is especially complicated, because not only our environment, but also the one from O365 is involved. O365 is mostly a blackbox, what means we don’t know and don’t need to care about the inner working of it.
We focus on what’s important for us, the consumer of O365 services: The hybrid setup of our local environment.
This is a blog post of a multi-part series. You’ll find the first post here.
Overview
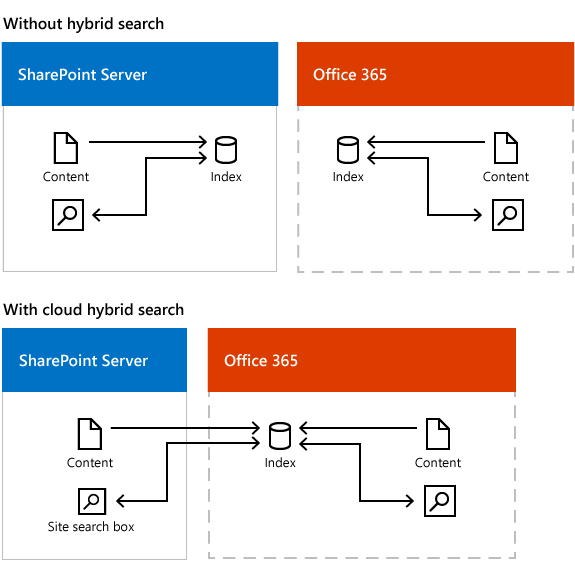
During the setup of the Cloud Hybrid Search, we create a new Search Service Application (we name it Cloud Search Service Application). This new service application crawls our onPremise content to feed it to Azure and ultimately to O365.
The Cloud Search Service Application consists of a different topology than the onPremise Search Service Application. The Cloud Search topology contains all search components, but only the Crawl component is active onPremise. The crawl component crawls the onPremise content and feeds it to the Azure Plugin. This plugin doen’t need any special configuration and sends the crawled content to the O365 search index.
This said, the logical conclusion is, that all your onPremise content (well, not all of it, but most of the textual content and metadata of the documents) is uploaded every full crawl.
This leads us to another topic to tackle:
Network Best Practices
A big topic. I can’t cover everything here, but I’d like to share our lessons learned.
Some timer jobs for synchronizing the content types or term sets failed. The Hybrid Picker couldn’t establish needed connections. Hybrid following was not possible.
Since the new endpoints are much further away, the latency is higher and sometimes too high when proxy servers or firewalls inspect the traffic from or to O365.
Microsoft published a list of all endpoints with inherent categories here. From there you can download the list in JSON format or as PAC (proxy auto config) file. The categories are explained here.
Conclusion
We covered only a tiny bit of the architectural considerations. Still, those are the most important ones. Without knowing about a second crawl component, that potentially consumes a lot of RAM, or without preparing your network settings, our planned configruations would be doomed to fail.